ViewPulse
i built a viewbot detector because a youtuber made me mad
not mad in a bad way. mad in a “okay fine, i have to do something about this” way.
if you watch MoistCr1TiKaL (Charlie), you’ve probably seen his video on the viewbot problem. the short version: fake viewers are a massive, underreported issue on Twitch. brands are paying for sponsorships based on viewer counts that are, in some cases, almost entirely fabricated. there are services charging a few hundred dollars a month to inflate your stream to 10k “viewers” who are just bots refreshing a page. nobody was doing anything about it in a way that felt… accessible.
i watched that video and thought “i could probably build something.”
so i did.
act one: StreamGuard
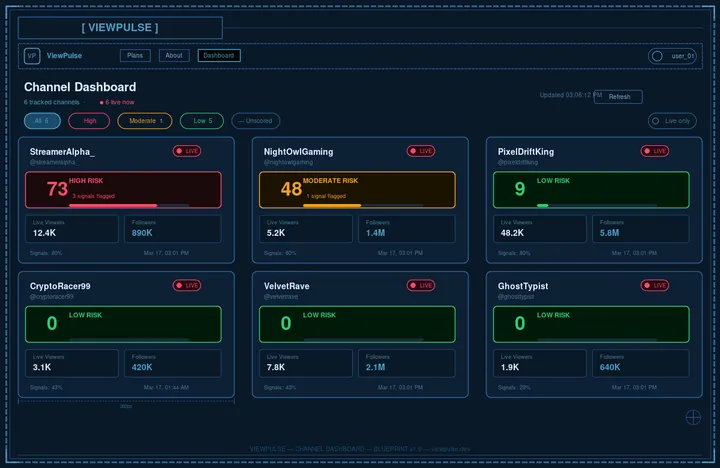
the project started under the name StreamGuard. it felt right at the time — something protective, watching over the stream ecosystem. i had a blueprint in my head pretty quickly: pull public Twitch data, run it through a scoring engine, give people a simple 0–100 suspicion score.
the first challenge wasn’t the product idea. it was the Twitch API.
Twitch’s Helix API gives you 800 API points per minute per client ID. sounds like a lot until you start modeling how many channels you want to monitor and how often you need to poll them. a naive implementation — hitting every channel every 60 seconds — runs out of budget around 100–150 channels and then starts dropping data. not great.
so the architecture had to be smarter from day one:
EventSub webhooks instead of polling. Twitch pushes a notification when a stream goes live. zero cost. instead of asking “is this channel live?” 86,400 times a day, you just… wait for Twitch to tell you. monitoring only starts when there’s actually something to monitor.
adaptive polling for active streams. once a stream is live, you check metrics every 5 minutes. but if you detect a sudden spike — viewers jumping more than 50% in one interval with no raid or host to explain it — that’s suspicious behavior, and you switch to 60-second polling for the next 30 minutes to capture it properly. spend budget where it matters.
credential pooling. multiple registered Twitch app client IDs, each with their own rate limit bucket, distributed round-robin. a totally legitimate technique that’s how most analytics tools scale.
with these three layers, you can comfortably monitor 400–600 channels simultaneously before hitting any real ceiling.
the scoring engine
the score itself comes from five signals, each weighted differently:
| signal | what it’s detecting | weight |
|---|---|---|
| viewer-to-chatter ratio | dead chat relative to viewer count — bots don’t type | 35% |
| viewer spike velocity | sudden jumps with no organic explanation | 25% |
| follower-to-viewer ratio | statistically anomalous ratio of followers to live viewers | 20% |
| historical pattern consistency | how does this session compare to this channel’s own baseline? | 15% |
| chatter username patterns | random strings and obvious bot-pattern usernames | 5% |
the viewer-to-chatter ratio is the strongest signal by far. real viewers chat. bot viewers don’t. a channel with 8,000 viewers and 12 chatters is a pretty clear pattern.
one thing i was deliberate about from the start: no hard verdicts. the tool produces probabilistic estimates, not accusations. a high score means “the signals suggest suspicious activity” — not “this person is definitely cheating.” that framing matters legally, but it’s also just honest. public data has limits. the score always ships with a data completeness indicator showing what percentage of signals were actually available for that session.
act two: the name problem
a few months in, i started noticing the name wasn’t landing the way i wanted.
StreamGuard sounds like a security product. something enterprise-y. something that guards your stream against… hackers? copyright strikes? it’s not wrong, but it’s not specific enough. when someone hears StreamGuard, they don’t immediately think “viewbot detection.” they think “stream protection software” in some vague, generic way.
the product had a clearer identity than the name did. it’s about viewing — specifically about whether those views are real. it surfaces the pulse of a channel. it watches.
ViewPulse.
that one clicked. it’s visual. it implies measurement. it nods directly to what the tool does: it reads the pulse of viewer activity and tells you whether what you’re seeing is alive or artificial. the domain was available. the social handles were available. we rebranded.
the technical rename was more involved than i expected. the GitHub repo, the local directory, the systemd service, the npm package names, SSH deploy keys, all the agent context files — everything had streamguard in it. took a solid afternoon to clean up properly, but it was worth doing before users showed up. renaming things post-launch is so much more painful.
where it is now
ViewPulse is live at viewpulse.dev. the core pipeline is running — EventSub subscriptions are active, snapshots are collecting, scores are generating. we’re monitoring real channels and the data looks like what we expected.
the stack:
- Next.js 14 (App Router) for the frontend, deployed on Vercel
- Node.js worker with BullMQ + Redis for the background polling pipeline
- PostgreSQL via Supabase for the time-series snapshot data
- all running on a Vultr Optimized Compute VPS (non-burstable CPU — a hard lesson learned from a previous project)
subscriptions are coming in April. the waitlist is open if you want in early.
why i’m telling this story
Charlie made a video about a problem. i watched it and thought there was a gap worth filling. that’s honestly how most of the stuff i build starts — not from a carefully researched market opportunity, but from “this thing bothers me and i think i can do something about it.”
if you’re sitting on an idea like that, the architecture isn’t actually the hard part. the hard part is deciding to start. the rate limit math, the scoring weights, the name — all of that figures itself out once you’re moving.
build the thing.
ViewPulse is live at viewpulse.dev. waitlist is open.